Validierung der Prognosegüte von Modellen des maschinellen Lernens über hochgradige Kreuzvalidierung ist der Standard für zuverlässige Aussagen. Wie man sich damit leicht selbst auf das Glatteis führen kann, davon erzählt diese Geschichte.
Hintergrund
Sommerschule für maschinelles Lernen unter Ressourcenbeschränkung
Der Sonderforschungsbereich 876 - Große Daten, Kleine Geräte, an der TU Dortmund führt regelmäßig Sommerschulen zum Thema Maschinelles Lernen unter Ressourcenbeschränkung durch. Ganz zum Forschungsgebiet des Sonderforschungsbereichs passend beschäftigen sich die Sommerschulen damit, wie die Analyse großer Daten, insbesondere auch auf eingebetteten Systemen und im Verbund mit sehr stark beschränkten Rechenressourcen, gelingen kann. Jede Sommerschule versucht dabei neben den eigentlichen Kursen auch einen Hands-On-Teil dazu anzubieten. Auch die innerhalb kürzester Zeit ausverkaufte Sommerschule 2017 war dabei keine Ausnahme.

Das Szenario war dazu an ein Problem aus der Warenlogistik angelegt: Wie finde ich im Regal meine Box wieder? Im Versuchsaufbau wurden zwei kleine Wände aus Warencontainern aufgebaut, wobei jeder Container mit einem im Projekt Ressourcen-effiziente und verteilte Plattformen zur integrativen Datenanalyse entwickelten PhyNode-Board versehen ist.
Aufgabe
Die PhyNodes sind stark ressourcenbeschränkte, autonome und weitestgehend energieautarke eingebettete Systeme mit einer Anzahl verschiedener Sensoren.

Die Aufgabe der Sommerschule bestand darin, das Lernen von Positionen von Boxen mit angebrachten PhyNodes für mehr als 20 Positionen als Labels zu realisieren. Später sollten die Boards selbst durch die Software auf den Boards ihre eigenen Positionen im Regal vorhersagen können. Die Teilnehmer erhielten dazu Trainingsdaten mit der bekannten Position. Die Boards nahmen im Verlauf verschiedene Positionen ein, d.h. ID des Boards und Position stimmten nicht immer überein. Die Messreihen zwischen dem Umstecken werden im Folgenden als “Experiment” bezeichnet.
Features
Verfügbare Features waren Zeit, Board ID, Temperatur, Luxwerte, Beschleunigungswerte X, Y, Z, RSSI zur Basistation, das Experiment und die Position als Label. Positionen bestanden aus zwei Ziffern mit der Bedeutung Spalte/Zeile, was für die Modellbildung aber keine Rolle spielte, da die Aufgabe zunächst als Klassifikationsproblem behandelt wurde. In Summe standen nach den ersten Experimenten mehr als 330.000 Messungen zur Verfügung.
Modellierung
Um einen ersten Eindruck von der Schwierigkeit des Problems zu bekommen (These: Das geht gar nicht) bietet es sich an beispielsweise eine schnelle Analyse mit RapidMiner auszuprobieren. Die Daten sind damit fix eingelesen und die wichtigsten Methoden mit ein paar Klicks verfügbar.
Der simple Ansatz ist dann: Daten einfach mit einem RandomForest mit Standardparametern (10 Bäume) gelernt, 10-fache Kreuzvalidierung und schauen, wo wir landen.
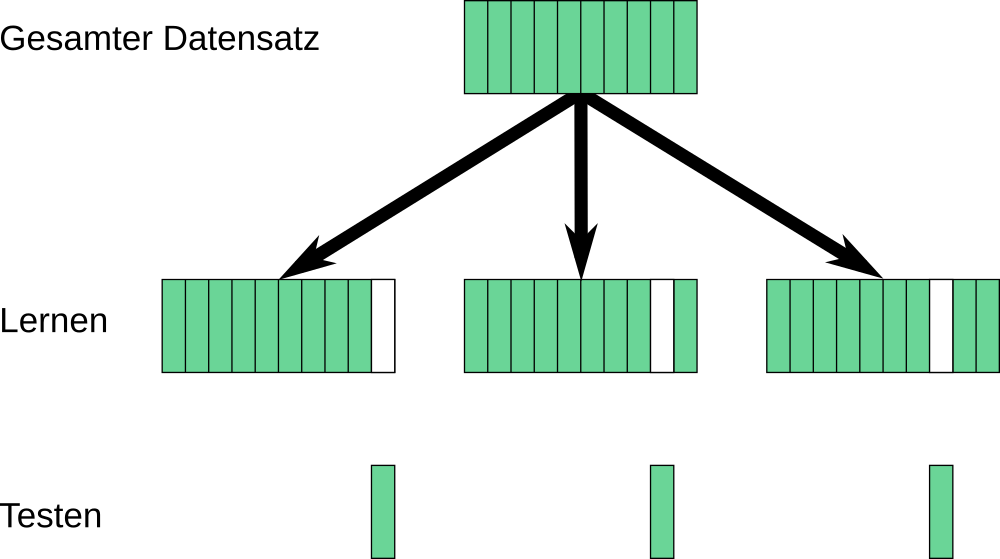
Die Kreuzvalidierung, insbesondere in 10-facher Ausführung stellt dabei sicher, dass unter maximaler Ausnutzung der Trainingsdaten ein sicheres Bild über die zu erwartende Güte gewonnen wird. Die Daten werden dazu gleichmäßig in 10 Blöcke unterteilt, wobei in jedem Trainings-/Testlauf ein Block für das Testing zurückbehalten wird, während die übrigen 90 % zum Training des Verfahrens zur Verfügung stehen.
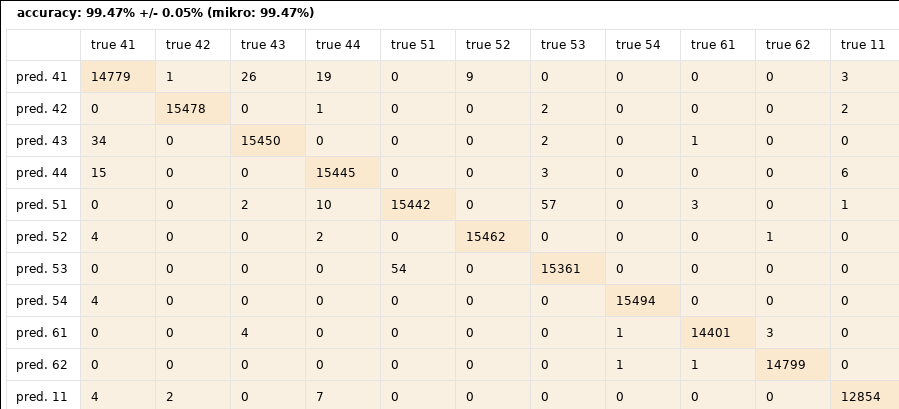
Für den Random Forest liefert diese Validierung dann auch eine Klassifikationsgüte von über 99 %. Ziel erreicht, perfekte Positionsvorhersage mit einfache Mitteln ist möglich, wir können nach Hause gehen. Schade um die Aufgabe, für eine Sommerschule war das dann wohl doch zu einfach. Naja, es blieb immerhin noch das Problem, das trainierte Modell auch auf die Ultra-Low-Power-Plattformen zu bringen.
Das Problem
Mehr als 99 %, und das ohne Aufwand. Hinterlässt aber irgendwie doch einen leichten Beigeschmack. Vielleicht lohnt es sich doch einmal etwas näher hinter die Kulissen zu schauen. Zur einfachen Interpretierbarkeit zeigt die folgende Abbildung den Ausschnitt aus einem einfachen Regelmodell anstelle des Random Forest.

So einfach sieht das Modell aber eigentlich gar nicht aus. Im Gegenteil eher überkomplex und overfittet. Auffällig ist die Einbeziehung der Beschleunigungs-Werte (Acc_x …). Welche Rolle sollten diese im statischen Fall, d.h. Boards bewegen sich nicht, spielen? Eigentlich sollte das Modell unwichtige Attribute selbst aussortieren.
Es scheint als ob die Beschleunigungs-Werte einen deutlichen Bezug zur Position und zum Experiment haben, quasi wie ein Fingerabdruck.
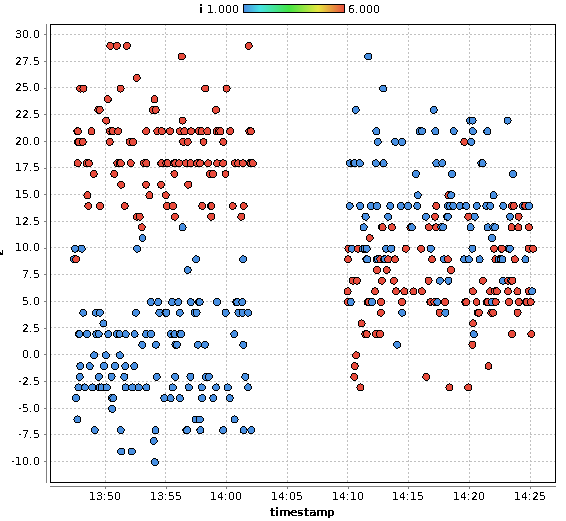
Der Plot zeigt beispielhaft den Z-Wert der Beschleunigungsmesser für zwei Boards (rot und blau) für zwei Experimente (entlang der Zeitachse mit kurzer Unterbrechung zum links und rechts). Die Werte sind im Mittel stabil, deutlich voneinander trennbar, und unterscheiden sich zwischen den Boards. Und nach dem Umstecken ändert sich der Z-Wert an der neuen Position. Was passiert hier? Sind die Sensoren so empfindlich, dass die Erdbeschleunigung unterschiedliche Höhen sichtbar macht?
Wohl eher nicht, eine viel ernüchternde Erklärung: Die Boards scheinen nach dem Umstecken immer leicht schief in den Boxen zu landen, was die Unterschiede in den Beschleunigungswerten ausmacht und die eindeutige Identifikation eines Boards an einer bestimmten Position ermöglicht. Leider sind diese Werte nicht reproduzierbar, damit nur Rauschen und nicht für ein in der Realität anwendbares Modell geeignet. Sobald Daten eines Experiments für die Aufteilung der Kreuzvalidierung für ein Board sowohl im Trainings- als auch im Testdatensatz vorkommen erzeugen diese den Fingerabdruck dieses einen Boards. Eigentlich sollten aber die Messdaten unabhängig vom Board Rückschlüsse auf die Position erlauben. Die Beschleunigungssensoren codieren damit (fast eindeutig) das Label (Information Leakage).
Und die Situation wird noch schlimmer: In den Daten sind 9 Experimente enthalten, d.h. 9 mal Umstecken der PhyNode-Boards an neue Positionen. In einer 10-fachen stratifizierten Kreuzvalidierung stecken damit immer sowohl in Trainings- als auch Testdaten Anteile aus allen Experimenten.
Wird die Kreuzvalidierung dagegen auf Batchweise umgestellt mit dem Experiment als Attribut für den Train-/Testsplit sehen die Ergebnisse ganz anders aus. Jetzt wird immer jeweils ein vollständiges Experiment für den Test zurückgehalten während die anderen 8 Experimente dem Training dienen. Schon sind es nur noch 10 % Genauigkeit, siehe dazu wieder einen Ausschnitt der Konfusionsmatrix für einen Random Forest mit derselben Parametrisierung wie zuvor.
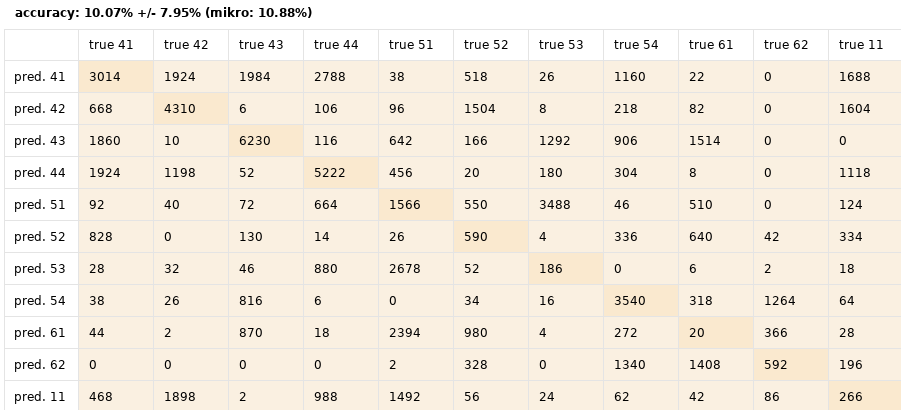
10 % bei mehr als 20 Labeln ist immer noch besser als raten, aber nicht beeindruckend. Immerhin ist damit zumindest die Basis für eine korrekte Validierung gelegt und der eigentliche Zyklus aus Modellwahl und Parametrisierung kann beginnen.
Was sich in dem Szenario dann letztendlich erreichen lässt haben die Kollegen anschließend in einer Publikation auf der Smart SysTech 2018 gezeigt. Mit viel Mühe sind damit immerhin wieder Klassifikationsgüten von über 80 % möglich.