Jetzt ist es hier einige Zeit recht ruhig gewesen, woran lag das? Nun, zu Einem gab es viel zu tun (wann gibt es das nicht?) und zu Anderem war da immer noch diese lästige Problem der instabilen Internetverbindung, was doch immer irgendwie im Hinterkopf schwebt (genaus wie die Klagen zuhause, dass Internet wäre ständig weg). Die Analysen und Spekulationen haben entsprechend Zeit gekostet bis immerhin ein (nicht ganz befriedigender) Workaround zu finden war.
Was bisher geschah
In Der Feind in meinem Haus ging es das erste Mal um Probleme mit dem Internet. Damals brach unregelmäßig die Verbindung vom Router zum WAN ab, Ursache unklar. Erste Vermutungen brachten einen mDNS-Storm verursacht durch Google-castfähige Geräte ins Spiel, was ungefähr auch zu diesem Zeitpunkt durch die Presse ging. Das mDNS-Problem war real, die (alleinige) Ursache war es aber nicht. Also weitersuchen und letztendlich bliebe nur eine Störungsmeldung beim Provider.
Ursachensuche
Um dem Provider nicht unpräzise mitteilen zu müssen: Internet fällt aus. Wann, wie oft? Weiß nicht, gefühlt immer dann wenn man es braucht. war der erste Schritt überhaupt einmal mitzuloggen, wann es überhaupt zu Problemen kommt. Vielleicht zeigen sich da schon Regelmäßigkeiten. Als schnell ein Skript erstellt, das eine externe Webseite aufruft, auf dem Raspberry, der sowieso 24/7 läuft, installiert und erst einmal Daten gesammelt.
#!/bin/bash
while true; do
dt=$(date +%Y%m%d_%H%M%S)
wget -q --tries=5 --timeout=30 --spider http://<seite_des_vertrauens.com>
if [[ $? -eq 0 ]]; then
echo "$dt:Online"
else
echo "$dt:Offline"
fi
sleep 30
done
Die Auswertungen geben dem Gefühl der “ständigen” Ausfälle wenigstens ein konkretes Gesicht: Wie lange, wie oft?
library(tidyverse)
library(lubridate)
du <- read_delim("dsluptime.log", delim = ":",
col_names = c("Time", "Status"),
col_types = cols(
Time = col_datetime("%Y%m%d_%H%M%S"),
Status = col_factor(levels = c("Offline", "Online"))
))
du %>%
filter(Status == "Offline") %>%
group_by(day=wday(Time, label = TRUE, week_start = 1)) %>%
count(day) %>%
ggplot(mapping = aes(x = day, y = n * 0.5)) +
geom_col() + labs(x = "Wochentag", y = "Summe Ausfallzeit [Minuten]")
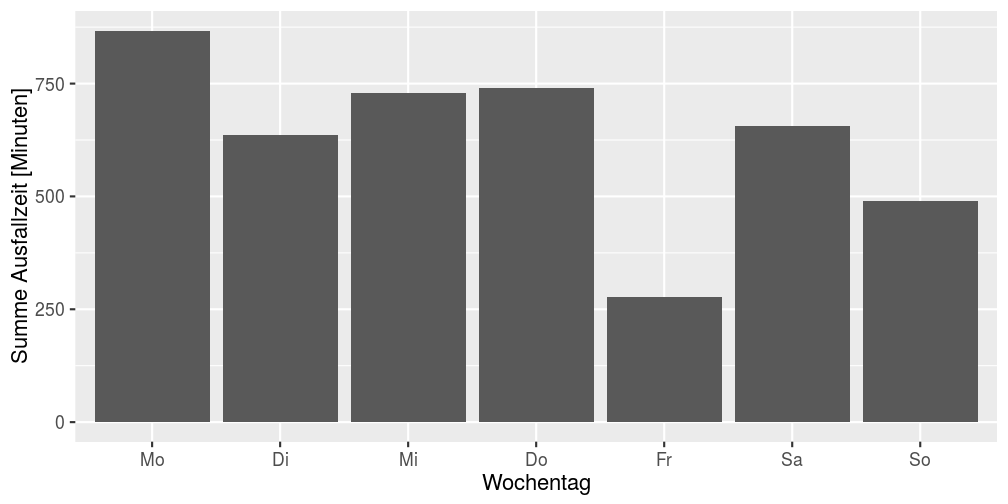
Die Summe der Ausfallzeiten je Tag ist zwar nicht gleichverteilt, aber richtig interpretierbar sieht es auch nicht aus. Auffällig sind die im Vergleich geringen Ausfälle an Freitagen, das Wochenende ist (überraschenderweise) ebenfalls leicht weniger betroffen, weicht aber nicht allzu stark von den übrigen Wochentagen ab.
du %>%
filter(Status == "Offline") %>%
group_by(day=hour(Time)) %>%
count(day) %>%
ggplot(mapping = aes(x = day, y = n * 0.5)) +
geom_col() + labs(x = "Stunde", y = "Summe Ausfallzeit [Minuten]")
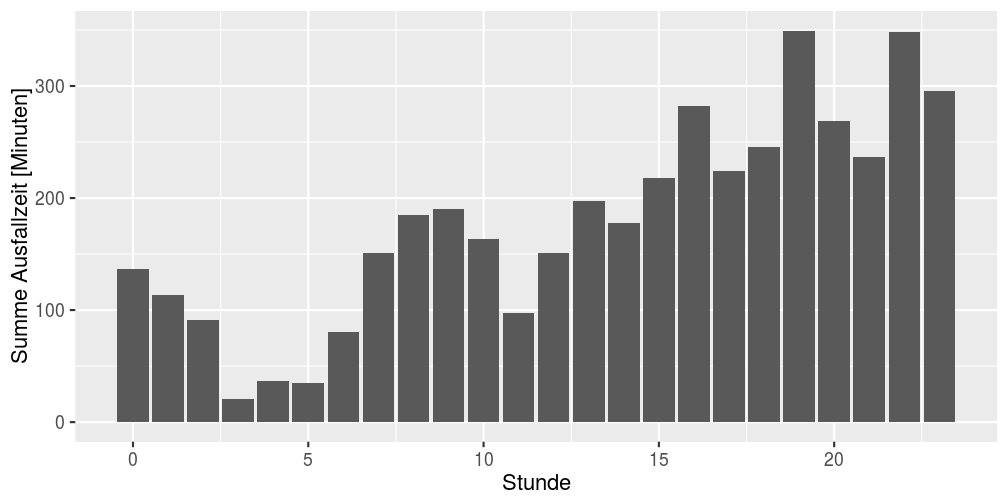
Bei der Betrachtung der Ausfallzeiten gestaffelt nach Stunden zeigen sich die meisten Ausfälle in den Abendstunden, was eine gewisse Abhängigkeit von der generellen Auslastung erahnen ließe.
du %>%
filter(Status == "Offline") %>%
group_by(date = as_date(Time)) %>%
count(date) %>%
mutate(wday = wday(date, label = TRUE, week_start = 1)) %>%
ggplot(mapping = aes(x = wday, y = n * 0.5)) +
geom_boxplot() + labs(x = "Wochentag", y = "Dauer je Ausfall [Minuten]")
du %>%
filter(Status == "Offline") %>%
group_by(hour=hour(Time)) %>%
group_by(date = as_date(Time)) %>%
count(hour) %>%
ggplot(mapping = aes(x = factor(hour), y = n * 0.5)) +
geom_boxplot() + labs(x = "Stunde", y = "Dauer je Ausfall [Minuten]")
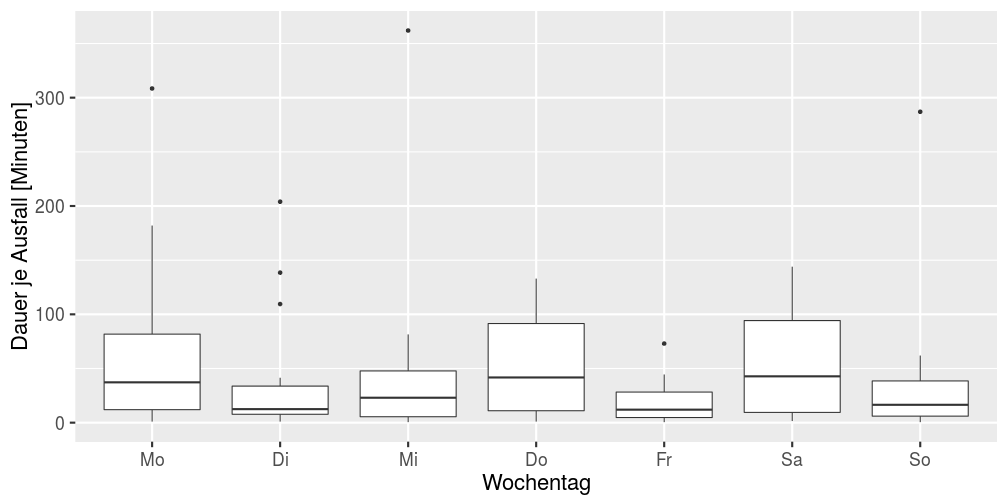
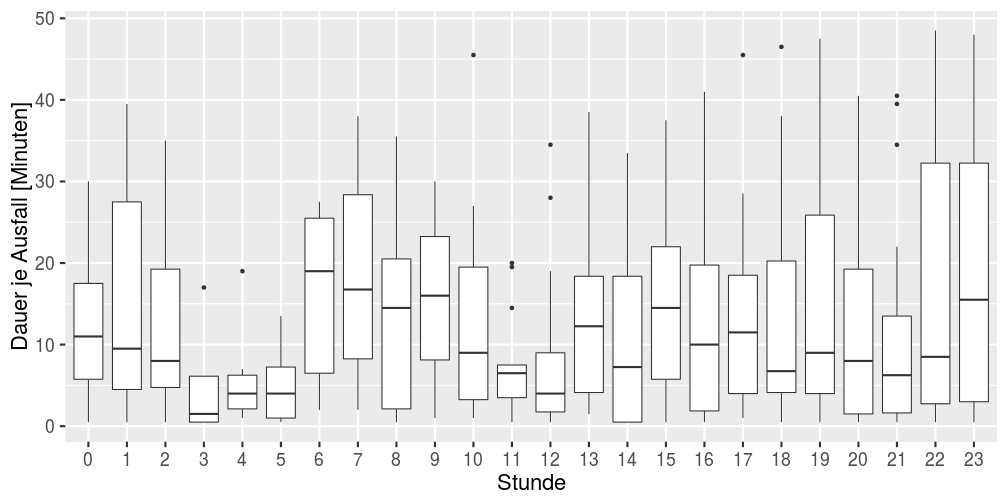
Die Boxplots der Ausfälle aufgeteilt jeweils nach Tagen und Stunden (Summe innerhalb jedes einzelnen Tags, jeder einzelnen Stunde an jedem Tag; d.h. zwei Ausfälle innerhalb derselben Stunde werden zusammengefasst) sollen einen möglichen Zusammenhang zwischen den Tagen/Stunden mit insgesamt einer hohen Ausfallzeit und der Dauer innerhalb dieser Stunde zeigen. Bestätigt hat sich das nicht. Hohe Werte für die Gesamtsumme (z.B. in den Abendstunden) ergeben sich nur durch mehr Ausfälle an mehreren Tagen. Insgesamt zeigt sich aber eine hohe Varianz wie schlimm/lang ein Ausfall sein kann.
Lösungsversuche
Damit scheint dann aber fast klar: Der Provider ist schuld und der Knoten überbucht. In den Abendstunden häufen sich die Ausfälle, wenn alle anderen auch Datenverkehr erzeugen. Also wird nichts anderes übrig bleiben als ein Supporticket zu öffnen und eine Lösung zu suchen, hmpf. So der Plan. Bis wir in Urlaub gefahren sind. Das Ticket ist aus Trägheit noch nicht eröffnet, schließlich funktioniert der Internetzugang irgendwie ja doch immer mal wieder, und Lust auf Gespräche mit der Hotline besteht auch nicht.
Und im Urlaub? Nur ein einziger kurzer Miniausfall, was auch alle möglichen Ursachen haben kann. Sollte das Problem doch bei uns im Haus liegen? Während des Urlaubs war WLAN komplett deaktiviert, Internetverkehr nur durch das Skript zum Verbindungsstatus und Kleinigkeiten wie hin und wieder mal ein NTP-Synchronisation.
WLAN jetzt woanders
Die Easybox 804 wird in Foren gerne für ihr WLAN kritisiert. Falls dort das Problem läge, ließe sich das mit anderer Hardware lösen. Gefallen ist die Wahl auf einen Ubiquit Unifi Accesspoint AC AP Lite, der in Bewertungen als recht konfigurierbar und stabil gilt, aber für kleine Setups eine recht umständliche zu nutzende Konfigurationssoftware besitzt. Die Reichweite der Easybox war zwar in Ordnung, aber ein zweiter Accesspoint sollte eh die Abdeckung verbessern.
Angeschafft, konfiguriert, WLAN an der Easybox abgeschaltet, und geholfen hat es nichts.
Bis zu dem Zeitpunkt als während des Ausräumens der Waschmaschine wieder der Ruf kam: “Kein Internet!”. Ein zufälliger Blick auf den Switch zeigte zwei wild blinkende LEDs, merkwürdig. Gehören tun sie zum neuen Access Point und dem Router. Da war wohl gerade ziemlich Last auf der Verbindung und über den Router sollte eben nur Datenverkehr ins Internet gehen. Im Wohnzimmer zeigt die beste Gattin der Welt zum Beweis des fehlenden Internets auf ihr Huawei P10. Auch andere Geräte im Haus haben kein Netz und der Router selbst loggt wieder seine WAN-Disconnects. Die Bitte, das P10 auszuschalten zeigt zunächst keine Wirkung (wie auch, Android-Smartphones sind ja nicht wirklich aus wenn der Bildschirm aus ist, sondern treiben wer weiß was im Hintergrund) und erst das echte Herunterfahren bringt die LEDs zum Schweigen, bzw. Dauerleuchten. Internet ist prompt auch wieder da…
Logging voraus
Da wäre als ein Kandidat als mögliche Ursache für die Verbindungsabbrüche vorhanden, aber was macht das Smartphone da überhaupt? Wird der Router überlastet wie potenziell bei den mDNS-Broadcasts (wobei der ein wenig Datenverkehr schon aushalten sollte).
Jetzt hat sich die Anschaffung eines Smart-Switches doch noch gelohnt. Den Port zum Festnetz-PC als Monitoringport konfiguriert und Wireshark mitlaufen lassen um zu sehen, wie viel Datenverkehr wohin überhaupt vorkommt.
# Aufzeichnung nur für einen Client (hier das Smartphone)
# und Beschränkung auf 50 MByte-Dateien
dumpcap -i eth0 - -b filesize:50000 -f "host <clientip>" -w trace.pcap
Und in der Tat zeigt das Log gleich mehrere Datenverbindungen zu unterschiedlichen IP-Adressen und volle Auslastung im Upload und auch nicht wenig im Download, allerdings nicht an der Maximalgeschwindigkeit. Immerhin besitzen wir hier eine ultraschnelle Breitbandanbindung mit bis zu 16 MBit/s im Down- und 1 MBit/s im Upstream. Und ich habe mal gedacht, wir würden im Ruhrgebiet, einer der dichtbesiedelsten Region Deutschlands, und nicht auf dem Land leben.
Im P10 selbst lässt sich zusätzlich auch für WLAN mit immerhin stündlicher Auflösung der Datenverbrauch von Apps anzeigen. Sortiert nach Datenvolumen zeigen sich die üblichen Verdächtigen: Google Fotos, Google-Backup-Transferdienst, K9-Mail, WhatsApp, PlayStore, HiCare, Wetterdatenservice, Instagram. Im Wireshark-Trace lässt sich dies über Reverse-Lookup der IP-Adressen zumindest teilweise nachvollziehen, jeglicher auffälliger Traffic würde darin aber vermutlich untergehen.
Energiesparen
Aber warum stürmen die Apps nahezu gleichzeitig auf das WLAN los? Eines der Feature (manche bezeichnen es aber auch als Bug) ist das aggressive Energiesparen im angepassten Android von Huawei. Kein Wunder, wenn die Prozesse beschränkt werden, schlafen liegen und dann gesammelt bei jeder sich bietenden Gelegenheit in den Wettbewerb der schnellsten Aktualisierung treten. Nur lässt sich daran etwas ändern und verschwinden die Verbindungsabbrüche, wenn sich die Datenverbindungen zeitlich entzerren lassen?
In der Huawei FAQ gibt es sogar einen eigenen Unterpunkt, der sich mit dem Wechsel auf WLAN beschäftigt, was auch der Fall wäre wenn das Gerät aus dem Standby erwacht. Zitat:
Nach der Verbindung mit einem WLAN-Netzwerk oder beim Umschalten zwischen einer WLAN- und einer mobilen Datenverbindung, warten Sie etwa 30 Sekunden, bevor Sie Apps verwenden, und überprüfen Sie dann, ob die Internet-Geschwindigkeit normal ist.
Strom sparen (versuchen) bis zum letzten Tropfen, aber die User Experience so weit vernachlässigen, dass es eines eigenen FAQ-Eintrags bedarf, ts. Das lässt sich technisch auch anders lösen.
Ein Versuch dies zu entzerren war die Energiespareinstellungen für die intensivsten Apps, insbesondere Fotos, zu deaktivieren und analog den unbeschränkten Datenzugriff, auch im Hintergrund, zu aktivieren. Wo diese Einstellungen liegen lohnt gar nicht zu dokumentieren, das ändert sich anscheinend öfter, denn fast alle Beiträge mit Beschreibungen, wo diese zu finden wären, waren schon veraltet. Für nicht ganz so wichtige Apps wurde der Datenzugriff gleich ganz verboten…
Aber es lässt sich schon erahnen: Gebracht hat es nichts. Über Maßnahmen wie Löschen des Caches oder Einstellungen in den Apps müssen wir auch nicht weiter reden. Irgendwann einmal hatte Google Fotos auch die Einstellung nur beim Laden zu sichern. Gone with the wind…
Bufferbloat
Eigentlich ist das Internet auf Fairness aufgebaut. TCP-Verbindungen sollten sich schön die verfügbare Bandbreite aufteilen, so dass für jeden etwas bleibt. Klar, insbesondere im schmalen Uplink bleibt dann nicht mehr viel übrig, aber ganz ausgehungert sollte keine Verbindung sein. Bis die Recherchen rund um die Verbindungsabbrüche auf die Seite über Bufferbloat geführt haben. Bufferbloat? Aber Speedtests waren doch alle in Ordnung? Nach Schwierigkeiten als der Anschluss noch neu war haben sich die Speedtests diverser Webseiten fast auf dem Maximum des Anschlusses eingependelt.
Aber Bufferbloat ist anders. Ist der Puffer bei einem der Geräte auf der Wegstrecke, und bei DSL ist dies üblicherweise der Router, zu groß, funktionieren die Ausgleichsmechanismen nicht mehr. Einzelne Pakete oder langsamere Datenverbindungen stecken dann im Puffer fest, die Latenzen schießen in die Höhe. Mittels einem kontinuierlichen Ping während eines Speedtests oder Tests wie fast.com von Netflix lässt sich das Problem relativ leicht nachvollziehen: Steigt die Latenz während einer ausgelasteten Verbindung an gibt es vermutlich ein Bufferbloat-Problem und letztendlich leidet auch hier die Nutzererfahrung. Und siehe da: Insbesondere im Uplink steigt die Latenz um den Faktor 10. Ist die Easybox die Ursache? Danach sieht es aus, müsste aber im Tausch mit anderen Geräten verifiziert werden. Vielleicht bekommt man eben doch nur das, was man bezahlt.
Aber, wir erinnern uns: Es sind nicht nur einzelne Verbindungen und Endgeräte, die den Kürzeren ziehen, auch die gesamte WAN-Verbindung fällt regelmäßig aus.
Workaround: Drosseln
So nicht zu erklären sind eben diese Abbrüche. Um eine Überlastung des Routers auszuschließen bleibt nur noch die Möglichkeit den Datenverkehr unter die Maximalgeschwindigkeit zu drosseln. Der Unifi Access Point bietet die Möglichkeit dies für gesamte SSIDs und sogar einzelne Clients zu tun. Hurra! Dann wird das P10 eben gebremst. Funktioniert aber nicht, hmpf. Scheint ein Problem in der aktuellen Firmware zu sein. Laut Ubiquiti-Foren kommt es öfter vor, dass Funktionen in der einen Firmware funktionieren und der nächsten wieder nicht. Auf Abhilfe zu warten ist nicht zielführend, also wieder auf den Smart Switch zurückgegriffen und den ganzen Port gedrosselt. Sicherheitshalber auf 10 MBit/s im Down- und 800 KBit/s im Uplink, was noch genügend Reserven zur Maximalrate lässt, aber gerade für Smartphones beim Browsen nicht allzu sehr auffällt. Dumm nur, dass damit auch alle anderen WLAN-Geräte betroffen sind, die vielleicht gerne doch in voller Geschwindigkeit im Heimnetz unterwegs gewesen wären.
Aber siehe da, seit der Drosselung kein einziger WAN-Verbindungsabbruch mehr. Natürlich besteht das Problem der im Endgerät lokal verstopften Leitung oder von Bufferbloat generell immer noch, allerdings in deutlich abgeschwächter Form und der Eindruck Internet weg entsteht gar nicht mehr. Damit lässt sich, zumindest temporär, leben.
Das Ende
Die eigentliche Ursache ist aber immer noch unklar und doch ein Fall für eine Störungsmeldung an den Provider. Überlastung, nur weil der Link voll ausgenutzt wird, dürfte auch im Consumergerät kein Problem sein. Mit üblichen Speedtests, auch mehrerer Datenströme parallel, ließen sich die Abbrüche nicht nachstellen.
Aber nicht zu jedem Ausfall der externen Internetanbindung sah der Datenverkehr nach einer wilden Ansammlung angestauter Datenverbindung aus. Ein einzelner Datenstrom konnte ebenso zum Ausfall führen.
QUIC (alias GQUIC), was ist QUIC? UDP-Datenverkehr und das auch noch auf Port 443 (https), welchen Sinn hat das denn?
QUIC ist ein auf UDP basierendes Protokoll, von Google ins Leben gerufen, als Testfeld für neue Managementalgorithmen für die Datenverbindung, unter anderem weil sich mit den normalen Standardisierungsprozessen z.B. auf TCP zu wenig/langsam Einfluss nehmen ließe. QUIC selbst ist schon einige Jahre alt (ich werde auch alt, das Protokoll kannte ich noch nicht) und findet zunehmend Einsatz in Google-Produkten. Und in der Tat zeigt ein Reverse-Lookup für die IP-Adresse auf Google-Server. Das muss allerdings noch nicht auf ein Google-Produkt als Quelle hinweisen, da unter Umständen auch die Nutzung von Google-APIs durch Drittentwickler QUIC nutzen könnte, allerdings waren diverse Google-Dienste und insbesondere die Foto-App in der Summe des Datenvolumens immer vorne mit dabei.
Ein Durchsatztest für QUIC scheint noch nicht zu existieren, das Protokoll ist auch noch im Standardisierungsprozess, also fix selbst einen Loadtest auf Basis einer freien Implementierung entworfen: QUIC-Loadtest.
# Server
quic-loadtest -s <publicip>:4242 -q -p 1300
# Client
quic-loadtest -c <publicip>:4242 -d 600 -q -p 1300
Aber auch dieser Test zeigt wunderbaren Durchsatz im Bereich der zugesicherten Geschwindigkeit. Als einziger offensichtlicher Unterschied zum Trace bleibt nur noch der Port 443. Also das Experiment noch einmal wiederholt, in diesem Durchlauf dann mit privilegiertem Port für den Server (entsprechend als Root, schön öffentlich erreichbar im gesamten Internet, also bloß schnell mit dem Test sein).

Und jetzt - endlich - bricht die WAN-Verbindung ab. Wiederholungen zeigen immer das gleiche Bild: Perfekter Durchsatz auf Port 4242 (ebenso auf 30, ebenfalls im Bereich der privilegierten Ports, aber keinem Protokoll zugeordnet), auf Port 443 dagegen nach 2 Minuten, spätestens nach knapp 10 Minuten Zwangstrennung. Ob durch den Router oder von außerhalb durch den Provider ist aus dem Log nicht zu entnehmen. Aber spätestens ab hier sieht es nach Absicht aus.
Warum nur wird die Verbindung nur bei UDP-Verkehr auf dem HTTPS-Port und nur unter Volllast beendet? Soll das eine Denial-of-Service-Abwehr sein, da UPD-Verkehr auf diesem Port eher ungewöhnlich ist (aber mit Google als Hauptnutzer dann doch wieder nicht so ungewöhnlich). Liegt einfach ein Fehlkonfiguration vor? Sind die Experimente nicht korrekt und das Problem liegt doch irgendwo anders? Um sicher zu gehen wären weitere und unabhängige Tests notwendig. Und warum sollte das keinem vorher aufgefallen sein? Ein dumme Kombination aus Anschluss, Router und Endgeräten?
Der First-Level-Support des Providers zeigte sich zwar noch interessiert und wollte das Vorgehen zur Reproduktion des Ausfalls an die Technik weitergeben, ein Techniker würde sich direkt zeitnah melden, passiert ist aber nichts.
Eine endgültige Auflösung wird es wohl nicht geben: Der Anschluss beim Provider ist sicherheitshalber gekündigt und das P10 hat Kontakt mit der Badewanne gehabt…